#include <memory.h>
Inheritance diagram for MemoryGrp
Public Methods | |
| MemoryGrp () | |
| MemoryGrp (const Ref< KeyVal > &) | |
| virtual | ~MemoryGrp () |
| int | me () const |
| Returns who I am. | |
| int | n () const |
| Returns how many nodes there are. | |
| virtual void | set_localsize (int)=0 |
| Set the size of locally held memory. More... | |
| size_t | localsize () |
| Returns the amount of memory residing locally on me(). | |
| virtual void* | localdata ()=0 |
| Returns a pointer to the local data. | |
| distsize_t | localoffset () |
| Returns the global offset to this node's memory. | |
| int | size (int node) |
| Returns the amount of memory residing on node. | |
| distsize_t | offset (int node) |
| Returns the global offset to node's memory. | |
| distsize_t | totalsize () |
| Returns the sum of all memory allocated on all nodes. | |
| virtual void | activate () |
| Activate is called before the memory is to be used. | |
| virtual void | deactivate () |
| Deactivate is called after the memory has been used. | |
| virtual void* | obtain_writeonly (distsize_t offset, int size)=0 |
| This gives write access to the memory location. No locking is done. | |
| virtual void* | obtain_readwrite (distsize_t offset, int size)=0 |
| Only one thread can have an unreleased obtain_readwrite at a time. More... | |
| virtual void* | obtain_readonly (distsize_t offset, int size)=0 |
| This gives read access to the memory location. No locking is done. | |
| virtual void | release_readonly (void *data, distsize_t offset, int size)=0 |
| This is called when read access is no longer needed. | |
| virtual void | release_writeonly (void *data, distsize_t offset, int size)=0 |
| This is called when write access is no longer needed. | |
| virtual void | release_readwrite (void *data, distsize_t offset, int size)=0 |
| This is called when read/write access is no longer needed. More... | |
| virtual void | sum_reduction (double *data, distsize_t doffset, int dsize) |
| virtual void | sum_reduction_on_node (double *data, int doffset, int dsize, int node=-1) |
| virtual void | sync ()=0 |
| Synchronizes all the nodes. More... | |
| virtual void | catchup () |
| Processes outstanding requests. More... | |
| virtual void | print (std::ostream &o=ExEnv::out()) const |
| Prints out information about the object. | |
Static Public Methods | |
| MemoryGrp* | initial_memorygrp (int &argc, char **argv) |
| Create a memory group. More... | |
| MemoryGrp* | initial_memorygrp () |
| void | set_default_memorygrp (const Ref< MemoryGrp > &) |
| The default memory group contains the primary memory group to be used by an application. | |
| MemoryGrp* | get_default_memorygrp () |
| Returns the default memory group. | |
Protected Methods | |
| void | obtain_local_lock (size_t start, size_t fence) |
| void | release_local_lock (size_t start, size_t fence) |
Protected Attributes | |
| int | me_ |
| int | n_ |
| distsize_t* | offsets_ |
| int | debug_ |
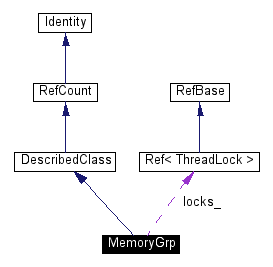
Several specializations are available. For one processor, ProcMemoryGrp provides a simple stub implementation. Otherwise, the specializations that work well are ShmMemoryGrp, ParagonMemoryGrp, and MPLMemoryGrp. If your parallel operation system and libraries do not directly support active messages or global shared memory you can try IParagonMemoryGrp or MPIMemoryGrp, as is appropriate. However, these latter specializations do not always work and perform poorly.
If a MemoryGrp is not given to the program, then one will be automatically chosen depending on which MessageGrp is used by default, the type of machine on which the code was compiled, and what options were given at configuration time. The following rules are applied until the first matching set of criteria are found.
\begin{itemize}
\item If a ParagonMessageGrp is used then:
\begin{itemize}
\item If the machine supports the full NX library (that is, it includes the hrecv function), then ParagonMemoryGrp will be used. The NX library is typically found on Intel Paragons and IPSC machines.
\item If the machine is an Intel Paragon running the Puma OS and it supports MPI2 one-sided communication, then PumaMemoryGrp will be used.
\item If the machine supports the NX library subset without hrecv, then IParagonMemoryGrp is used.
\end{itemize}
\item If an MPIMessageGrp is used then:
\begin{itemize}
\item If the has the Message Passing Library then MPLMemoryGrp is used.
\item Otherwise, MPIMemoryGrp is used.
\end{itemize}
\item If an ShmMessageGrp is used, then a ShmMemoryGrp is used.
\item If there is only one processor, then ProcMemoryGrp is used.
\item Otherwise, no memory group can be created.
\end{itemize}
|
|
Processes outstanding requests. Some memory group implementations don't have access to real shared memory or even active messages. Instead, requests are processed whenever certain memory group routines are called. This can cause large latencies and buffer overflows. If this is a problem, then the catchup member can be called to process all outstanding requests. |
|
|
Create a memory group. This routine looks for a -memorygrp argument, then the environmental variable MEMORYGRP, and, finally, the default MessageGrp object to decide which specialization of MemoryGrp would be appropriate. The argument to -memorygrp should be either string for a ParsedKeyVal constructor or a classname. |
|
|
Only one thread can have an unreleased obtain_readwrite at a time. The actual memory region locked can be larger than that requested. If the memory region is already locked this will block. For this reason, data should be held as read/write for as short a time as possible. Reimplemented in ActiveMsgMemoryGrp, ProcMemoryGrp, and ShmMemoryGrp. |
|
|
This is called when read/write access is no longer needed. The memory will be unlocked. Reimplemented in ActiveMsgMemoryGrp, ProcMemoryGrp, and ShmMemoryGrp. |
|
|
Set the size of locally held memory. When memory is accessed using a global offset counting starts at node 0 and proceeds up to node n() - 1. Reimplemented in ActiveMsgMemoryGrp, MsgMemoryGrp, ProcMemoryGrp, and ShmMemoryGrp. |
|
|
Synchronizes all the nodes. Consider using this when the way you you access memory changes. Reimplemented in MsgMemoryGrp, MTMPIMemoryGrp, and ProcMemoryGrp. |